데미스 하사비스(Demis Hassabis)는 체스 플레이어이자 뇌과학자 출신입니다. 2014년 1월 구글 딥마인드(Google DeepMind)의 공동 창업자이자 CEO가 되었죠. 특히 영국왕립협회(The Royal Society of London for the Improvement of natural Knowledge)의 특별회원이기도 합니다.
........
딥마인드는 크게 두가지의 방향성을 가지고 있습니다.
Intelligence 통해 해결하라.
그 Intelligence 를 이용하여 나머지 모든 것을 해결하라.
인공지능(AI, Aritificial Intelligence)는 기계를 더 똑똑하게 만드는 것을 목표로 하는 일종의 컴퓨터기반 과학/공학입니다. 하지만 그동안의 인공지능은 사람이 프로그래밍한 것으로써 모든 상황에 대한 해결책이 기계에 수작업으로 입력되는 방식이었습니다. 한가지 목적만을 해결할 수 밖에 없기에당연히 활용범위가 좁을 수 밖에 없었습니다. 예상치 못한 상황이 발생하면 그냥 고장나기 마련이죠. 이들에게는 '프로그램되어 있지 않은' 상황에 대처할 능력이 전혀 없기 때문입니다.
아마 지금까지 알려진 가장 유명한 인공지능은 IBM의 DeepBlue일 것입니다. 그는 1997년에 세계 체스 챔피언인 가리 카스파로프(Га́рри Ки́мович Каспа́ров)를 이겼습니다.
Deep Blue vs. Garry Kasparov (1997)Deep Blue vs. Garry Kasparov (1997)
Deep Blue vs. Garry Kasparov (1997)
데미스 하사비스는 이 경기가 열리던 1997년에 캠브리지에서 공부하고 있었다고 합니다. 그는 체스에도 꽤 능통했기 때문에, 이 게임을 유심히 관찰하였다고 합니다. 그가 발견한 딥블루의 문제점은 체스 외에는 아무것도 하지 못한다는 것입니다. 딥블루에 내장된 시스템과 프로그램은 오직 체스를 두기 위한 용도로만 작동하기 때문에, 오히려 그보다 더 쉬운 카드 게임이나 가위바위보 등은 전혀 하지 못한다는 사실입니다. 딥블루는 체스를 마스터했지만 그 지식을 가지고는 체스 외의 다른 어떤 분야에도 활용이 불가능했습니다. 반면에 개리 카스파로프는 '인간'으로써 기계만큼 체스를 잘 두었지만, 체스외에도 많은 것을 할수 있다는 사실이 데미스 하사비스에게 영감을 주었습니다. "사람처럼 생각하는 기계를 만들수 없을까?"
딥블루는 인공지능 역사에 있어서 엄청난 업적이긴했지만, 데미스는 더 큰 꿈을 갖습니다. 그것을 넘어서는 것이죠. 이는 결국 General AI(범용적인 인공지능)을 만들수는 없는가?에 대한 질문으로 귀결됩니다. 이러한 범용 학습이 가능한 예시는 바로
우리의 머리 속에 들어있는 녀석이죠. 이 뇌가 유일한 예입니다. 딥마인드는 이것을 가능케 하는 것을 목표로 하고 있습니다. 구체적으로 다음을 목표로 하는 범용 학습 알고리즘(General-Purpose Learning Algorithms)을 딥마인드에서 개발하고 있습니다.
Learn automatically from raw inputs- not pre-programmed : 이는 사전에 어떠한 수작업이나 프로그래밍 작업 없이, 순수하게 input값(기초데이터와 경험)만을 가지고서 스스로 학습하는 방식입니다.
General - same system can operate across a wide range of tasks : 이는 하나의 시스템으로 다양한 환경을 넘나들며 실행해도 아무런 지장이 없는 '범용적인' 시스템에 관심이 있습니다.
이것을 일명 Artificial 'General' Intelligence(AGI)로 지칭하겠습니다. 이는 범용적 인공지능으로써 Flexible하고 adaptive, inventive한 발상입니다. 일반적인 프로그램과는 다르게, 예상밖의 상황에 적절하게 대응할 수 있게되는 것입니다. 이를 구현하기 위해서 딥마인드는 다음의 두가지 방법을 채택하였습니다.
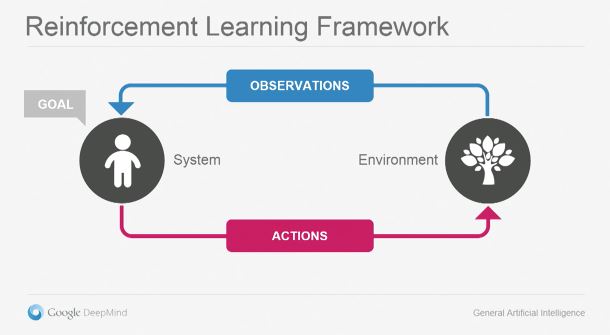
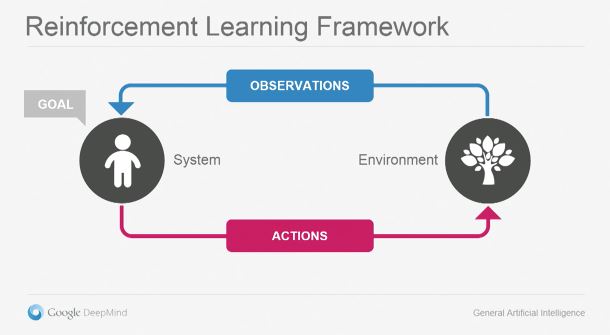
1. 강화학습(Reinforcement Learning Framework)
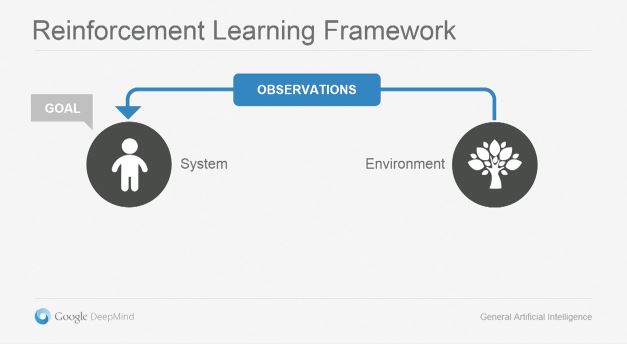
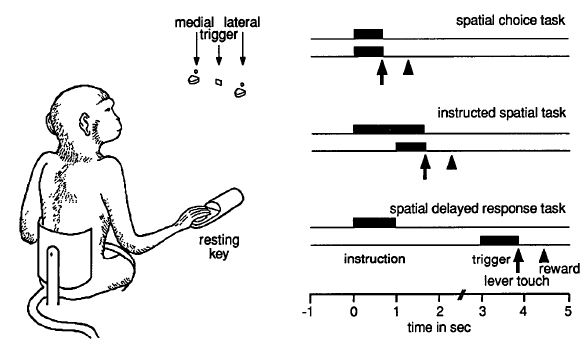
Agent는 어떠한 특수한 환경(Environment)에 속해 있습니다. 이 에이전트는 환경과 소통할 때 관찰과 행동이라는 두가지 방법을 사용합니다. 관찰은 감각기관을 통해 환경을 살펴보는 것입니다. 현재는 대부분 시각을 사용하지만, 앞으로는 그외의 다른 감각양식으로 확대될 것입니다. 이 시스템에서 중요한 점은 관찰내용에 불필요한 잡음(Noise)가 포함되어있어서 해석이 간단하지는 않다는 것입니다. 에이전트는 불완전한 관찰내용을 토대로 환경을 학습해야 합니다. 환경에 대한 모델이 만들어지면, 이를 이용해 현재 상황에서 가능한 다양한 방법 중에서 목표에 최대한 근접한 최적화된 행동을 선택해야 합니다. 무엇을 할지가 정해지면 그것을 실행에 옮기고 그 이후의 변화를 다시 관찰하는 작업을 실시간으로 반복합니다.
이 그림은 아주 단순해 보이지만, 이를 구현하기 위해서는 상당히 복잡한 기술이 필요합니다. 이대로만 실현할 수 있다면 인간과 같은 범용적 지능을 완성할 수 있을 것입니다. 이렇게 확신할 수 있는 이유는 이것이 실제로 생명체가 학습하는 방법이기 때문입니다. 동물들도 강화학습을 통해서 배우고, 인간의 뇌도 강화학습을 학습 방법 중 하나로 사용하고 있습니다.
이것을 증명하는 것이 90년대에 나온 원숭이를 통한 유명한 실험 결과입니다. (링크)
단일 신경세포의 신경 활성 패턴을 측정하는 실험으로부터, 도파민 신경세포가 예측오류정보(예측이 얼마나 틀렸는지를 나타내는 정보)를 처리하고 있음을 밝혀냈습니다. 이 말은 우리의 뇌 속의뉴런에 TD학습(Temporal difference learning:예측오류정보에 기반한 학습 알고리즘)이라 불리는 일종의 강화학습이 구현되어 있다는 것입니다.
2. 체화된 인지(Grounded Cognition)
딥 마인드에서 가지고 있는 두번째 방법은 체화된 인지라고도 불리는 그라운디드 코그니션입니다. 이 원칙은 실제의 생각하는 기계는 감각운동의 사실성에 기반을 두고 있어야 하며 이것이 현실에 기반을 둔 진짜 생각을 만들 수 있는 유일한 방법이라는 것입니다.
이렇게 위에서 명시한 방법들을 구현하기 위해 대부분의 학자들은 인공지능 로봇을 만듭니다. 실제 현실의 정보에 기반한 생명체를 흉내내기 위함이죠. 마치 터미네이터와 같은.
하지만, 로봇 제작은 굉장히 어렵습니다. 재료가 비싸고, 그 하드웨어를 컨트롤하는 것이 쉽지 않기 때문입니다. 엔진을 고치고, 그에 맞는 팔다리가 제대로 작동하도록 만드는데에만 상당히 많은 시간을 소비하게 됩니다. 하사비스는 '로봇'을 만든다기보다, '지능 소프트웨어'를 만드는데 목적이 있었기에 하드웨어보다는 알고리즘 구현에 더 집중하고자 했습니다.(회사 설립 초기의 재정적 한계도 있었겠죠)
그래서 그는 비디오 게임을 통해 인공지능 알고리즘을 테스트해보면 좋겠다는 생각을 하게됩니다. 게임이 가장 완벽한 플랫폼 역할이 될 것이라는데에는 몇가지 이유가 있습니다. 단지 게임을 오랫동안 플레이하도록 시킴으로써 거의 무한대에 가까운 연습 데이터를 손쉽게 만들수 있다는 것이고, 검증 오류도 적기 때문입니다. 과거에 인공지능을 만들 때 알고리즘을 만든 사람이 검증까지도 함께 해야하는 문제점이 있었습니다. 아무리 객관적으로 평가하려고 해도 무의식적으로 자신의 알고리즘에 어울리는 편파적인 검증방법을 채택하게 된다는 것입니다. 하지만 '게임'을 통해 검증한다면, 게임 개발자들이 이미 만들어놓은 룰이 있고, 점수(Score)를 통해 에이전트가 게임을 학습하면서 점점 똑똑해지고 실력이 늘고 있는지를 객관적이면서도 한눈에 파악할 수 있습니다. 이 때문에 딥마인드는 게임을 검증 플랫폼으로 사용하였습니다.
이와 관련하여 하사비스는 다양한 시청각 자료를 준비하였는데, 그와 동일한 자료를 찾아서 다음번 포스팅때 이어서 업로드하도록 하겠습니다.
..................
지난 글에 이어..
'게임'을 통해 인공지능을 테스트한다면, 점점 똑똑해지고 실력이 늘고 있는지를 게임 속의 '점수'를 통해 아주 편리하게 알아볼 수가 있습니다. 그리하여 딥마인드는 게임을 검증 플랫폼으로 사용하기 시작했죠.
이것은 End-to-End 학습 에이전트입니다. 이 말인즉슨, 화면에 보이는 픽셀값(특별히 전처리되지않은)이 입력되어 실행에 옮겨지는 것입니다. 즉, 인식에서부터 실행에 이르기까지의 전체 과정을 포함합니다.
Deep Reinforcement Learning
딥마인드의 최대 혁신인 "심화 강화 학습"(Deep reinforcement Learning)은 바로 인식하는데서 실행까지 가는 데에 있는 모든 과정, 그리고 이 모든 다양한 분야들을 모두 다루는 것입니다. 딥러닝을 통해 인지하는 절차를 밟고, 강화학습이 결정을 내려 실행에 옮깁니다. 즉, 딥러닝과 강화학습을 합침으로써 다양한 스케일의 문제에서 강화학습 알고리즘을 적용시킬 수 있게 해줍니다. 그리고 이를 일반화시켜서, 하나의 시스템으로 다른 모든 게임을 플레이 할 수 있도록 하고자 합니다.
아타리(Atari)는 세계 최초의 비디오 게임이다.(1972)아타리(Atari)는 세계 최초의 비디오 게임이다.(1972)
아타리(Atari)는 세계 최초의 비디오 게임이다.(1972)
그들이 처음으로 시도해본 대상은 80년대에 있었던 고전적인 게임인 아타리(Atari) 게임입니다. 에이전트에게 주어지는 정보는 전 처리되지 않은 픽셀값만이 유일합니다. 아타리 게임의 화면 크기는 가로200 * 세로150 픽셀크기이므로, 프레임당 3만개의 숫자가 입력됩니다. 에이전트의 목표는 단순히 '최고 점수를 내라!'는 명령입니다. 에이전트는 모든 것을 처음부터 스스로 배우기 시작합니다.
중요한 것은, '어떻게 조종하는지', '어떻게 점수를 내는지', '게임의 규칙이 무엇인지'에 대한 정보를 프로그래머가 전혀 주지않았습니다. 이 모든 것은 스스로 배워야 합니다. 심지어 인접해 있는 픽셀들이 시간에 따라 조금씩 변해진다는 것조차 모릅니다.
그들이 먼저 테스트해본 게임은 '스페이스 인베이더'입니다. 처음에 에이전트는 아무런 연습경험이 없습니다. 그래서 그냥 이것저것 막 눌러봅니다. 화면 아래에 있는 초록색 로케트를 막 조종하다보면, 아래에 있는 3개의 목숨이 닳아서 죽어버립니다. 이 에이전트는 자신이 뭘 하고 있는지, 무엇을 해야하는지를 아직 모르지만- 목숨이 닳으면 더이상 게임을 플레이할 수 없다는 것을 점차 깨닫기 시작합니다.
에이전트가 게임을 밤새 20시간 정도 하도록 놔두고, 다음날 와서 보면, 이제 굉장한 실력의 플레이어가 되어있습니다. 총알을 발사할 때마다 모두 적을 섬멸합니다. 분홍색 우주선(고득점 이벤트)가 날아올 때 놀라울 만큼 정확하게 맞춰서 보너스를 획득합니다.
그리고 이 게임은, 적의 숫자가 적어질수록 적의 이동속도가 빨라집니다. 에이전트는 이 특성을 학습했기 때문에, 적이 어디쯤 올 것이라는 것을 예상하여 마지막 한발을 발사하고 명중시킵니다. 놀랍지요.
보시는 바와 같이 게임을 하는 에이전트는 시간에 따른 정보의 변화를 완벽하게 모델링하고 마스터하였음을 알 수 있습니다.
두번째 게임은 '벽돌 깨기'입니다.
이 게임은, 바닥에 있는 판을 조종해서 상단에 있는 무지개색의 벽돌들을 하나씩 부수는 것입니다.
에이전트는 100게임을 하는 동안, 그다지 좋은 실력을 갖추지 못하고 번번히 공을 놓칩니다. 하지만 '공을 떨어뜨리면 게임이 끝나는구나!', '판을 공쪽으로 움직여서 받아내야 하는구나!'를 깨닫기 시작합니다. 이런 학습을 통해 에이전트의 실력은 조금씩 단계적으로 좋아집니다. 300판을 지나면 에이전트는 어려운 각도임에도 불구하고 거의 빠짐없이 공을 받아내고 있습니다. 보통 인간이 할수있는 수준을 살짝 넘어서고 있습니다.
'아주 잘하는군, 하지만 200게임을 더 하도록 놔두자'.. 하고 총 500게임을 플레이하도록 실험해보았습니다. 놀랍게도 에이전트는 벽돌의 가장자리에 구멍을 뚫어서 공을 윗층으로 올려 보내는 최적의 전략을 짜서 게임을 하기 시작했습니다. 상당히 놀라운 정확도였습니다. 이것이 에이전트가 짜낸 최상의 전략이었습니다.
한쪽 모서리에 구멍을 내어 공을 집어넣었다.
한쪽 모서리에 구멍을 내어 공을 집어넣었다.
사실 이 시스템을 만든 연구원이나 기술자들도 아타리 게임을 잘 모르고, 이런 전략을 전혀 생각해내지 못했었습니다. 거꾸로 이 에이전트 시스템으로부터 사람이 무언가를 배운 것이지요. 아타리 게임에 한해서는 '일반성'이 있는 인공지능을 만들어낸 것입니다. 차례대로 여러가지 다른 게임들입니다. 보시다시피, 하나의 에이전트가 이 모든 게임을 플레이하고 있습니다.
Enduro
River Raid
Battle zone, 해적과 싸우는 게임, 초창기의 3D게임 등, 이 모든 게임들은 각기 다른 규칙을 가지고 있는데, 이를 모두 마스터한 것입니다.
pong
이 초록색 바를 조종하는 탁구게임은 항상 20대 0으로 이깁니다. Seaquest (잠수함 게임) 외에 여러가지 다른 게임들도 그러합니다.
Boxing
이 복싱게임의 왼쪽에 있는 선수는 스파링을 하다가 구석으로 몰아넣고 끝업이 점수를 얻습니다(일명 꼼수) 이제 게임을 쉽게 이기는 전략까지 터득한 것입니다.
이것을 이를 DQN(Deep Q-Network)에이전트 라고 부릅니다.
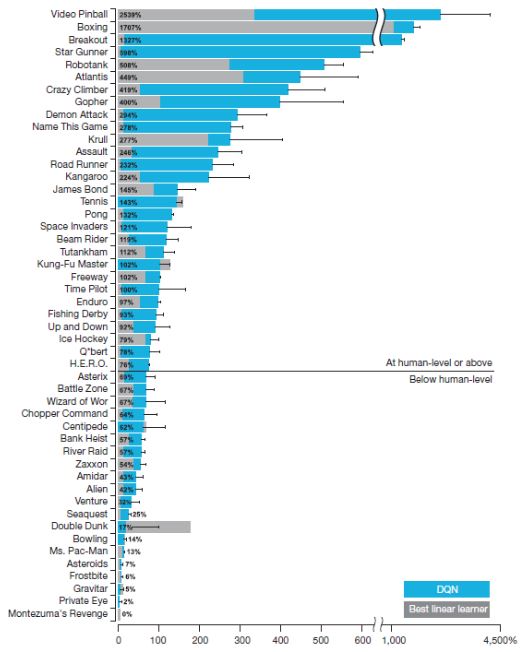
Comparison of the DQN agent with the best reinforcement learning methods in the literature.
이처럼 에이전트가 기초자료만 가지고, 직접 시행착오를 겪으며 스스로 학습하여 게임을 마스터하고, '일반성'을 가진 것은 이번이 처음입니다. 이와 관련된 자료는 네이처 저널 표지 논문으로 실린 링크를 통해 더 깊이 확인하실 수 있습니다. 실행코드를 받아보실 수 있고, 직접 DQN을 활용해 보실 수 있습니다. 모두 네이처 웹사이트에 있습니다. (첨부파일)
attach_file
playing Atari with Deep Reinforcement Learning.pdf
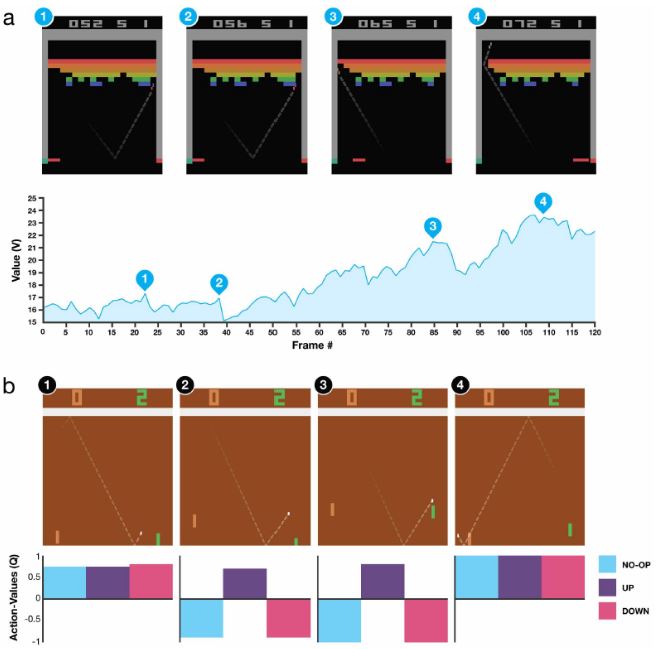
Visualization of learned value functions on two games, Breakout and Pong
Visualization of learned value functions on two games, Breakout and Pong
그렇게 아타리와 2D게임에서 현재는 3D게임으로까지 발전했습니다. 이번에도 역시 전처리 되지 않은 순수한 픽셀값만을 가지고 경기장에서의 운전을 배우게 되었습니다. 에이전트는 200킬로 넘는 속도로 운전을 하고, 꽤 멋지게 추월하며 차를 조종합니다. 또한, 퀘이크 엔진을 이용해서 3D 미로 문제를 해결하는 장면입니다.(Mazes)
이 에이전트는 이 미로에서 사과같은 아이템을 찾을 때까지 달려갑니다. 미로가 어떻게 생겼었는지를 정확하게 기억하여 나가는 길을 찾습니다. 역시나 픽셀정보만을 가지고서 플레이하는 것입니다. 딥마인드에서는 더욱 복잡하고 정교한 3D 학습 환경을 만들고 있습니다. 이러한 결과는 올해 말 정도에 논문으로 개제될 예정입니다. 또한 현재는 로봇 시뮬레이터 작업도 하고 있습니다. 곧 실제 로봇 작업을 할 것입니다.
아시다시피, 요즘은 바둑(이세돌과의 대결)에 관심을 쏟고 있습니다. 이와 관련된 내용이 이어지는데 다음 포스팅에서 뵙겠습니다.
출처













 현재 총 134명 접속중입니다. (회원 1 명 / 손님 133 명)
현재 총 134명 접속중입니다. (회원 1 명 / 손님 133 명)